Using LLMs to parse and understand proposed legislation
Legislation is famously challenging to read and understand. Indeed, such documents are not even intended to be read by the average person. They are primarily tools for lawyers, ministers and judges. But we still need public scrutiny of them. If these documents are inaccessible to the majority of people, then it’s far easier for laws to be made without adequate democratic participation and feedback.
Note: Most countries, one hopes, have a way of encoding law (or acts, statutes, codes, regulations), and additionally a way of amending law. I live in the UK so my project focuses on UK-style parliamentary procedure.
Disclaimer: I still only have a very rudimentary understanding of this stuff so apologies for any inaccuracies or oversimplifications.
If you attempt to read through UK Legislation you’ll find most documents strung together with archaic lawyer-speak, cross-references, and allusions to previous legislation and existing mechanisms of government. Here, for example, is a quote from a recent Act of Parliament: the Illegal Migration Act 2023:
“The Secretary of State may provide consent under subsection (5)(a) only if the Secretary of State considers that there were compelling reasons for the person not to have provided details of the matter before the end of the claim period.”
Out of context it’s pretty confusing. Here’s a similarly lawyer-y nugget from the Interpretation Act 1978:
In the application of this Act to Acts passed or subordinate legislation made after the commencement of this Act, all references to an enactment include an enactment comprised in subordinate legislation whenever made, and references to the passing or repeal of an enactment are to be construed accordingly.
And this one is from the Companies Act 2006:
Any reference in such a document to the company’s constitution shall be construed in relation to a resolution required to be passed as mentioned in subsection (1)(a) as including a reference to the requirements of this chapter with respect to the passing of such a resolution.”
These aren’t impossible to parse, but, much like any legal document, in order to understand and internalise their meaning, you need a very detailed understanding of the larger context, and the underlying instruments of law.
In the UK, legislation is typically encoded in Acts of Parliament like those above. These can be considered law. And if you wish to change the law, then you’ll need to prepare a Bill! A Parliamentary Bill will detail proposed changes to an Act, in the form of amendments, insertions, and deletions.
Here’s a quote taken from the Economic Crime and Corporate Transparency Bill:
1 “After section 195L insert — “195LA Prior authorisation of seizure of terrorist cryptoassets (1) Where an order is made under paragraph 10Z7AC in respect of a cryptoasset-related item, the court, sheriff or justice making the order may, at the same time, make an order to authorise the seizure […]
This is similar in style and sheer obscurity to the above quotes from Acts of Parliament, but it has a fundamental difference. It describes amendments, insertions and deletions to the underlying Act. So, by necessity, it has meta-language that tells us where new things will be amended.
If you’re a programmer, this may remind you of “changesets”, used in version control systems like Git to encode proposed changes to code. You may recall the joyful rigamarole of creating branches, accruing changes, partaking in multiple pull-requests and rebasing attempts, merging back into a feature branch,… which, when completed, might finally allow you to merge into ‘main’. That’s all this is, really. Here’s a meatier analogy to the exact passage a bill takes through parliament:
Initial Commit = First Reading: The formal introduction of the Bill to Parliament in either the House of Lords or the House of Commons.
Pull Request = Second Reading: General debate on the Bill’s principles and themes.
Code Review/Debugging = Committee Stage: Detailed examination, debate, and amendment of the Bill’s content.
Final Review = Report Stage: Further opportunity to amend the Bill.
Accepting the Pull Request = Third Reading: Final chance to debate the Bill, but no more amendments allowed.
Peer Review = Other House: Bill undergoes similar stages in the other House.
Resolving Merge Conflicts = Consideration of Amendments: Review and decision on changes made by the other House.
Merging into Main = Royal Assent: The Bill is applied to the Act, and that Act becomes law.
Challenge Accepted.
You can see the massive difficulty that lies before the average citizen if they desire to engage with this process. As such this seemed ripe ground for Large Language Models (LLMs) to help us out! AI — yay!
I pondered; could I use OpenAI GPT-4 (combined with Anthropic’s Claude) to create a “good enough” bill parser, that’d enable me to -
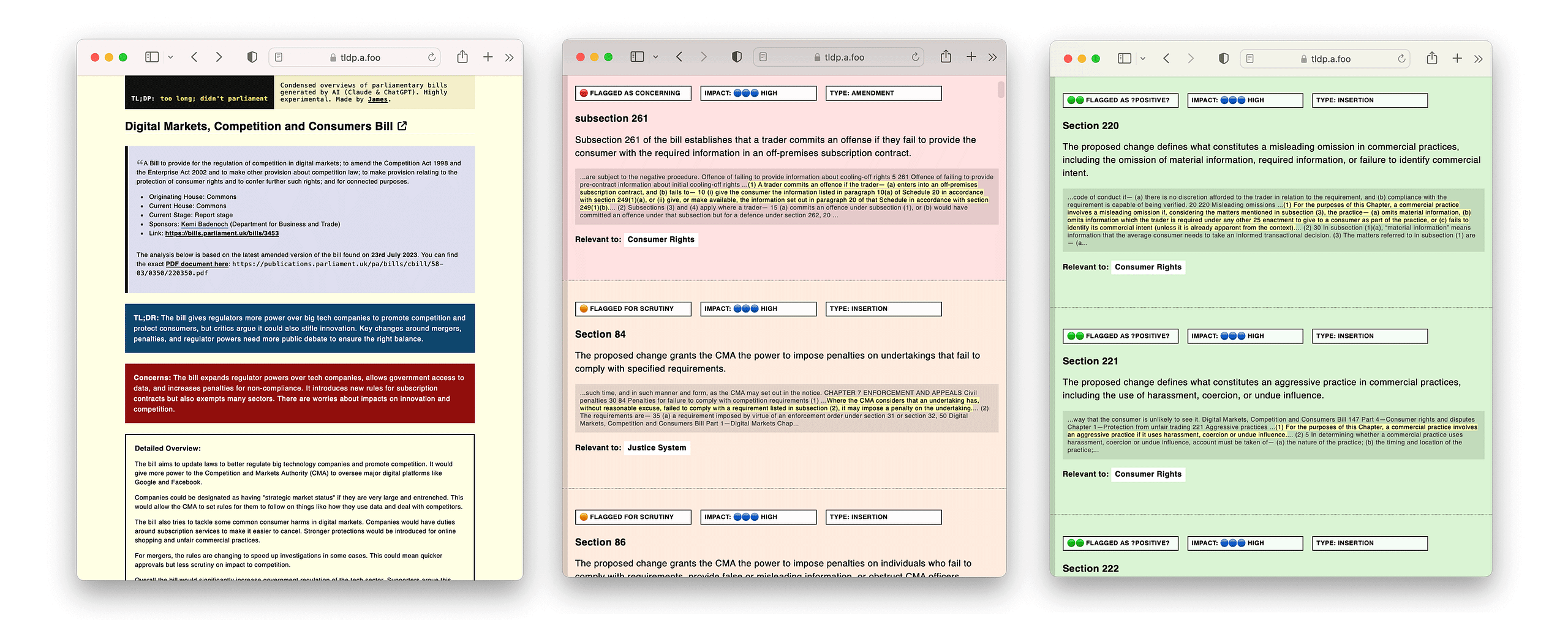
Get a high-signal TL;DR [“too long; didn’t read…”] summary of what a bill is trying to accomplish.
Get an idea of the main concerns or areas that may warrant more scrutiny.
See individually flagged amendments, insertions and deletions to give me even more insight into the most potent parts of a bill.
The implementation in prospect seemed simple enough. Just give the LLM the whole Bill and the underlying Act, and let it get to work! … Simple.
Jokes aside, this actually does get you something decent, if prompted well. But you need to do a bit of heuristic dancing to get the outputs you desire. What lies most in our way are dreaded context lengths…
Alas, Context lengths
The Number 1 biggest issue when LLMs meet legal documents is *context size*. LLMs-as-a-service (OpenAI, Anthropic, etc.) are typically limited to anything from 8k tokens to 32k+. Anthropic’s Claude 2 supposedly has 100k context length but apparently uses a bit of heuristic trickery to accomplish this. Either way, the largest bills and acts are too big for us to take the simple approach of throwing the content wholesale at the LLM.
There are a couple ways to deal with this. If you’re only looking for an overview of a semantically consistent document (that broadly centres around a fixed topic), then you can often truncate or remove entire chunks to get a representative sample that is under the token limit.
But what if you don’t want to miss anything?
There are many ways to tackle this. The solution I landed on was to have a kind of ‘cursory’/scanning approach where I would prompt the LLM in a way where it “understood” that the text it’s receiving is only a small part of a larger document, and it’s job is to extract only certain things from each chunk. In this case, I’d ask it to extract proposed changes in the the subset of the bill it’s been given, and then, to summarise and flag items in the context of the larger bill. Here’s an example of a prompt I would send to ChatGPT 3.5turbo 16k (the largest context size available from OpenAI that I have access to).
The text you're provided is just a subset of a larger document, in this case a UK Bill that modifies an Act (legislation). Here is a summary of the entire bill:
You will only receive a small chunk of the bill at any one time. So, from this limited text, and ONLY THE TEXT, you identify ALL identifiable CHANGES within the text itself. Do not presume to know what exists outside of the text you're given.
Changes of HIGH relevance that you MUST record with priority:
- Establishment of new institutions, committees, entities, governmental bodies. - Repeal or amendment of existing laws - New regulations or regulatory frameworks - New powers granted to the government - New reporting/oversight mechanisms - Budgetary/funding allocation - Changes to bureaucratic processes - Expansion/restriction of individual rights - Criminalization/decriminalization - Territorial governance changes
For each identifiable change, you output: <change> <type></type> <subject></subject> <! - one or more quotes… → <quote></quote> <summary></summary> <impact></impact> <clarity></clarity> …
[further prompting here] [including a more thorough breakdown of the desired schema]
Each call to GPT only had access to one chunk of the entire document, and was tasked with only extracting items from what was currently in its “view”. Here’s an illustration of that:
Extracting, Annotating, Flagging
As alluded to with the prompt above, I’m asking GPT to (attempt to) give me:
Indication of how impactful a change is likely to be.
What pillars of society it probably affects.
Whether it’s flaggable for more scrutiny.
These are obviously really subjective things to ask of an LLM, but again, we’re just looking for something “good enough” to escalate notable stuff within the bill up to me, the lowly citizen attempting to get a handle on this monstrosity of a bill.
For the measure of impact we set it out like so:
<impact>
<!-- Valid values: 1|2|3|4|5|Unknown -->
<!-- Explanation: "Impact" assesses the noteworthiness and significance of the change.
Here are the different values' meanings:
Unknown = Unintelligible or unclear.
1 = Minor/Semantic: Changes are minor, non-substantive, or just rewordings without modifying legal or societal implications.
2 = Moderate: Changes could potentially affect legal processes significantly, though not guaranteed or immediate.
3 = High: Changes will certainly cause significant shifts in legal processes, affecting how laws are enforced, prosecuted, or defended.
4 = Massive: Changes dramatically reshape the legal landscape, impacting major legal institutions, concepts, or established precedents.
5 = Revolutionary: Changes overhaul existing legal structures or concepts or introduce wide-ranging new legal mechanisms or institutions that change the fabric of society. -->
</impact>
And on the client we can map these over to pretty emojis or whatever we desire:
For so-called “pillars of society” we set out them in the prompt, like so:
<pillars>
<!-- Analysis of the change as it pertains to key societal pillars. -->
<pillartype="Gender and Sexuality"> <!-- brief analysis IF APPLICABLE of any of the given pillar types... --> </pillar>
<pillartype="Education"> <!-- brief analysis here --> </pillar>
<pillartype="Human Rights"> <!-- brief analysis here --> </pillar>
<!-- ... Etc. other relevant pillars go here... -->
<!-- These are the pillar types:
- National Security - Social Welfare - Economic Impact - Political Power - Public Health - Education - Human Rights - Justice System - Cultural Impact - Gender and Sexuality - Race and Ethnicity - Disability - Minority Groups ... -->
</pillars>
They’re not exhaustive by any means, but just an attempt at extracting something of use.
Flagging is the most contentious thing I’m asking the LLM to make a judgement of:
<!-- This flag indicates the proposed change's aggregate effect on humanitarian and progressive ideals such as an increase in human rights, social welfare, gender equality, etc.
For simplicity: Green = Good, Red = Bad.
RED= Obviously negative effect (e.g. racial profiling) YELLOW= Questionably negative effect (e.g. reduction in public scrutiny of government) WHITE= Very little effect (e.g. semantic or unimportant change) BLUE= Possible positive effect (e.g. higher budget for libraries) GREEN= Obviously positive effect (e.g. more protections for minorities) -->
</flag>
This is very obviously imbued with my own biases of democracy, equality, non-bigotry and general welfare. But, heh, I think that’s alright. I’m creating a tool foremost for myself, and secondarily as a technical experiment. If this was used by the general populace then yes it would need to be able to flag based on the users’ concerns and biases, as contraversial as they may be.
A rundown of the entire process
A quick overview of how we go from a Parliamentary Bill PDF to a rendered extraction/analysis:
Extract text from the bill; this can be automated with pdf-to-text libraries but for now I’m doing this manually in Acrobat. The main issue with this is that page and column numbering sometimes gets mixed up in the text, which for an LLM isn’t really an issue, but if you’re looking to use the text as a canonical source, e.g., for quote retrieval, then you’ll have issues.
Split into chunks based on token lengths; this involves using reasonable heuristics to split at a place where we’re not slicing sentences in half. It’s a good idea to split at paragraph or page endings. Ideally we’d be able to identify different structural sections of a document.
Send each chunk to GPT with the aforementioned prompt including meta information like bill summary, title, date, sponsors, etc. (it’s good to play with this to engineer the best possible prompt). I run these generations with a “temperature” param of 0.0 so that results are deterministic; these are much easier to debug and better optimise the prompt.
Parse the “faux” XML from each response; It’s “faux” because it sometimes will stop at strange points or include malformed tags. Using a forgiving XML parser is best. GPT-function-calling would make this simpler, although even OpenAI states that the JSON may be malformed. Anyway, following XML parsing, we can join up all the `<change>` elements and pop them into an aggregate document ready for the next step.
Generate TL;DR, Overview & “Concerns” categories manually with Claude2; it has a sufficiently large context size that you can pass the entire XML.
Render nice static HTML pages with NextJS. One notable technical challenge here is to find the quotes that the LLM has reflected back to us (`<quote>`) within the original document. But with a bit of work, it’s easily achieved.
Post-processing challenges
Just to give you an illustration of the types of post-processing you tend to need to do when you want to clean up LLM outputs…
As mentioned I’ve had to find a way to locate quotes from within the raw bill when the LLM tells me what it’s found with the <quote> tags. It should be a simple substring matching process but the raw text from the PDF is noisy because of column/page numbers that can’t easily/heuristically be removed, and the LLM often intelligently (…unhelpfully) removes that noise. I ended up with a best-effort (1) normalization (remove redundant characters) and (2) a binary-substring-search. This seems to work for most cases. If a quote is not found we can assume that the LLM messed up so we can reject that change anyway. This is a useful check to confirm the LLM isn’t hallucinating entire quotes! Gosh, imagine.
// E.g. findIndexOfChangeFromQuotes( ["26A Duty to notify Commissioner of unlawful\ direct marketing (1) A provider of a public\ electronic communications"], rawNormalizedTextBill );
functionfindIndexOfChangeFromQuotes(quotes, rawSearchableBill) { let index = -1; let foundQuote = null; quotes.find(quote => { foundQuote = quote;
This kind of stuff is always going to be necessary. You need to have a way of observing and cleansing the outputs you received. Never assume they’re right.
Another fun one was dealing with cut-off XML outputs. This seems to happen even if you inflate the amount of tokens you ask for (max_tokens):
//... perChunkProcess(result, index) { if ( result.content.match(/<\w+>/g).length !== result.content.match(/<\/\w+>/g).length ) { console.error('Chunk #', index, 'Unmatched XML tags'); // Shortening by un-ideally throwing away everything // beyond the last </change>
Having to truncate stuff from an output is annoying because you don’t know if you’ve missed high-signal changes, but I have to remind myself that the main goal here is not an exhaustive analysis, but instead a “best effort” TLDR/flagging tool, so that citizens like me have a better chance of understanding and applying more scrutiny to these proposed legislations. Fundamentally: LLMs are not precise machines, they are lossy, noisy, messy, but–somehow–still useful.
FWIW, there are still many approaches one could use to deal with these “lost” outputs. You could, for example, run smaller and overlapping chunks through GPT, potentially resulting in redundant results. This would require some clever deduplication/normalization.
There are a bunch of other silly challenges related to cleansing, but you get the idea. They’re all surmountable.
And here is an example of (1) the summary section (2) some ‘negatively’ flagged amendments and (3) some “positively” flagged amendments.
Closing thoughts…
This whole endeavour was not as complicated as I originally thought it would be. I just had to throw stuff at the LLM and keep playing with the prompt until I get something reasonably structured and accurate enough. By “reasonable” I mean, in this context: an overview of a bill that is even marginally better than the status quo of inaccessibly fat documents that no average citizen would have time nor motivation to read through. I hope I’ve demonstrated that.
A note on the GPT function-calling API: I imagine many people just assume the function-calling API the best way to return structured data. I’ve experimented with it but I’ve found that it doesn’t seem to imbue the schema with the same level of semantic precision. What I mean by this, I guess, is that my messy prompted XML schema seems to drive the model to output more meaningful changes. It’s simply… better. Function-calling is probably better for extraction of simpler content? Perhaps I just need to play with it more.
Ways to improve:
Very important: both qualitative and quantitative quality control. How do we know the LLM has given us something accurate? My suspicion is that it’s around 70% accurate, with lots of fuzzy partially-correct assessments around the edge. Not much wholesale wrong, but the platform is definitely not sufficient for professional consumption. Perhaps though it’s useful enough for citizens or advocacy groups to do an initial sweep/scan.
It would be useful to map proposed changes to the original act so more context can be available to the LLM. This is something I thought I’d have to do. However, it turns out that the bill itself, along with the trove of the LLM’s knowledge (the aggregate corpus its been trained upon up till a couple years ago), I didn’t need to do this to achieve my “Good Enough” MVP.
Show the timeline/passage of the bill through parliament in a more detailed way and give users direct ways of escalating or collaboratively flagging concerns. Link to sites where members of parliament can be held to public scrutiny (e.g. TheyWorkForYou.com).
Thanks for reading. Thoughts and feedback welcome! See more of my projects and read more about me here.
PS. I’m looking to open-source the code but it needs a bit of a tidy-up first.