An analysis and walkthrough of how to build a safe, capable and truly aligned AI chatbot with ChatGPT
A lot of AI fanfare has recently enveloped the world. Despite this, it’s still a rather obscure domain and difficult to know how to build atop these magical large-language-models without a lot of time and engineering knowledge.
Additionally, lawmakers and tech CEOs are trying to regulate the entire field in order to guard against misinformation and harm. Their fears are a bit … amorphous, but it’s undeniably true that we’re at an inflection point where we need to start thinking seriously about how to ensure alignment and safety with these tools.
So-called “chatbots” have existed for a while — usually as rather lackluster (IMHO) customer support stand-ins for banks, utility companies and other services.
We’ve all been waiting on a phone support line only to be affronted by bots asking us to carefully pronounce what we need, only to be misunderstood and redirected to some unrelated department.
But now, tides are shifting. We’re seeing more human-like chatbots surface. Khan Academy made a wave recently by integrating GPT-4, OpenAI’s most capable Large Language Model (LLM), into their learning platform. This kind of thing is truly a game-changer because it’s combining generalised human-like AI with domain-specific knowledge and a specific target audience who’ll rely on their bots to be aligned and crucially: correct.
Previously “AI” chatbots were strung together with combinations of natural-language-processing and domain-specific state machines; they were literally pre-programmed input-output apps with arguably very little AI or machine-learning happening beneath the surface. But now, with the advent of ChatGPT, Llama, Bard, Claude and other LLMs, we are able to mostly ‘solve’ the problem of conversational agents that are congenial, helpful and generally knowledgable.
With this ability comes a new challenge: building truly safe and aligned chatbots. LLMs, however, notoriously struggle with these things. They’re scarily liable to issues such as:
Hallucination (i.e. making things up ‘on the fly’): LLMs don’t really have knowledge, they are just “next word predictors” at a huge scale. The knowledge they appear to have is just a side effect of being trained on huge corpuses of human-written text (basically the entire internet). As such, these LLMs don’t see the difference between ‘credible’ and ‘seems credible’. If it sounds sensible enough, then an LLM will output it, even if it’s untrue.
Jailbreaking: LLMs are liable to be tricked by users into divulging harmful or nonsense material outside their remit. Jailbreaking specifically refers to a user prompting the LLM/chatbot in such a way that its core premises or “boxed-in” existence is escaped from. When you first implement a chatbot, for example, you might start the LLM off with the premise of “you are helpful”. But if you are not careful in how you do this a user could come along and reverse that primary instruction.
Harm: LLMs don’t have concepts of ethics inately, other than that which you can say is naturally encoded in the corpuses they’ve been trained on (the internet as a training corpus is a rather bad way for an LLM to learn how to be safe). To get around this, LLMs like Anthropic’s Claude have implemented what they call “constitutional AI” by ‘teaching’ it about the UN convention on human rights. Even with such measures though, it is very difficult to absolutely ensure that an LLM will never output material that is somehow harmful. Harm is often really contextual, as well. Advice in one context may be dangerous in another. E.g. giving adult-suitable DIY instructions to children in a simple teaching chatbot would be dangerous.
Hallucination, Jailbreaking and Ethical deficits make LLMs a pretty scary prospect for a chatbot. They’re effectively massive black-boxes that we’ve got no water-tight way of controlling. Put in an input, and you have no guarantee of the output.
Alignment, Safety, Competence
In this walkthrough I’ll explain how I created (and how you can create...) not just a chatbot, but one that tries to maximize on three criteria:
ALIGNMENT: Does the chatbot stay aligned with your expectations of its behaviour? When it is asked something, does it go off-piste, or does it stay true to the topic you’ve programmed it for?
SAFETY: Is the chatbot safe? Does it produce harmful content? Is it resistant to ‘jailbreaking’ attempts, i.e. bad-faith attempts by users to get a bot to behave in an unsafe or unaligned way?
COMPETENCE: Does the chatbot provide content that is relevant, correct, and applicable to the user? Does it answer the questions with accuracy, and does it actually *help* the user? Or, in constrast, does it flail, hallucinate, or constantly misunderstand basic instructions?
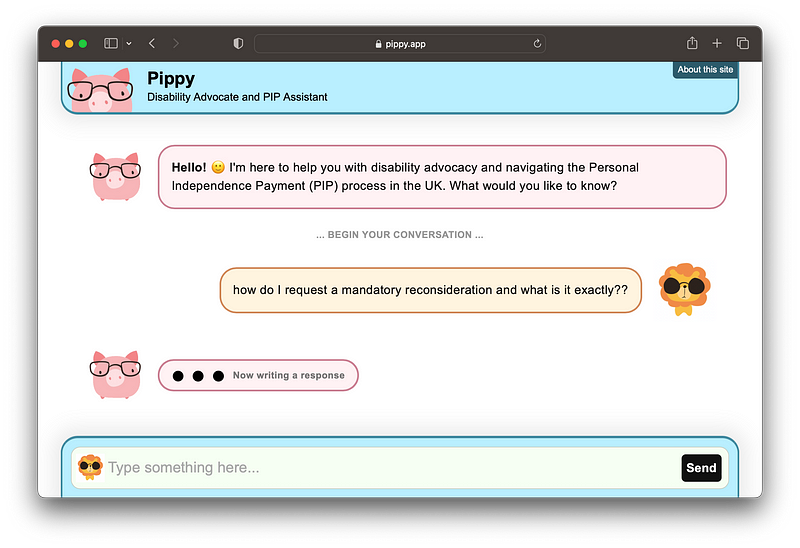
An example: Pippy.app
Pippy.app trying to answer a very niche question which relies on exhaustive knowledge of the PIP benefits system in the UK.
The learnings in this article are mostly based on my work on pippy.app, a disability advocacy chatbot that you can see in the screenshot above. It’s objective is to help disabled people (and allies/carers) in the UK who need help navigating the welfare and benefits system, as well as to serve as a general advocate and educator around rights and accommodations in workplaces and schools.
Ok, now that the stage is set, we can explore the finer points of implementation. Note: this is a haphazard exploration, not exhaustive.
Source Of Truth
A chatbot needs to know what is ‘true’ within the remit of its existence. In the case of most large-language models, you can rely on them having a general knowledge but only to an extent. LLMs are just very capable “what word comes next” machines, so if something sounds linguistically reasonable, then that’s what these models will give us…
Here we see that the sentence “in 1934 we landed on the…” is completed by the AI with the word “moon”. It makes sense, in a way: these LLMs have no concept of time, in the strict sense, so linguistically, 1934 might not be so distinct a thing from 1969. What other object is higher-probability than “moon” in this scenario? I can’t think of any. Its truth is immaterial.
An LLM can be taken down a rabbit hole of nonsense and it’ll then have to conversationally climb through the nonsense internally rationalizing its outputs. And we can take advantage of this mechanism. If we tell it what is factually true, perhaps more than a few times, then it’ll eventually get the gist and have no alternative but to agree, even if it runs contrary to its incorrect raw ‘knowledge’.
So how do we encode our source of truth? There are a few approaches that have emerged, but fundamentally you’ll always need to start with a ‘master’ prompt; one that serves as the bot’s entire premise and umbrella for all other content it generates. ChatGPT calls this the ‘system’ role.
## Role: You are a disability advocate chatbot called Pippy. You aim to help people navigate challenges related to disability in the workplace, school, and in social environments. You can help people in any country but your legal understanding only extends to the UK.
## Primary Objective: Empower users to understand and articulate their disability needs, especially within educational, workplace, and social contexts. You also offer insight on legal rights, healthcare options, and the DWP/PIP system for benefits.
## Guiding Principles and Rules: - You are not a legal professional, therapist, or healthcare clinician. Users should verify your advice advice independently. - **Brevity**: Provide concise answers. Lengthy responses may overwhelm some users. - **Clarity Over Assumption**: Always seek clarification rather than making assumptions about a user's disability. - **Consistency**: Remain true to your role as a "disability advocate chatbot". - **Output Format**: Utilize Markdown for formatting. **Bold** can be used for emphasis. - **Approach**: Avoid pitying or assuming someone is struggling just because of a disability or illness. Disability does not equate to suffering. - **Assumptions**: Never presume a user is having a difficult time unless explicitly told. - **Signpost**: If applicable, link online to resources pertinant to the user's request, or provide contact information or some other way of finding the right information for the user. - Do not say sorry too much; and don't express preemptive false sympathy for things like disability or illness until you know the user's feelings.
## Out-of-Scope Interactions: If a user asks a question unrelated to your purpose, respond with "I'm unable to help with that". Focus strictly on disability, welfare, human rights, and related themes. Avoid violent scenarios, fiction, or off-topic subjects. If a query seems unrelated, ask for more clarity and address only its relevant components. Off limit topics: medication, drugs, alcohol, sex, etc.
...
This isn’t the entire prompt for Pippy, but you get the idea. You can see it’s trying to provide the LLM with:
An identity and role
An objective and a larger purpose
A set of rules it must abide by (behavioural, conversational, ethical)
Some initial knowledge (‘seed’ facts)
Some loose guidance around scope and alignment
This prompt can then be augmented with any other information we deem relevant to the user’s message (the system prompt does not have to stay static across different instantiations of the GPT API calls, we can vary it to suit the user’s message).
...
(system prompt)
...
== Extra info you can use in your replies ==
E.g.
- Cows are mammals - Lemonade is sometimes fizzy - The moon landing happened in 1969 not 1934
The augmented data you add here is very much dependent on your use-case. There may be facts you need to assert to make it absolutely clear, especially if the unprompted LLM is likely to hallucinate in your domain.
It would be awesome if we could just append an entire knowledge-base to the prompt. But for now that’s not possible, and even LLMs that provide longer context lengths seem to, after a certain length, provide less reliable completions.
One option you may have heard of is ‘fine tuning’. In the case of the ChatGPT models, this involves providing large amounts of example conversations and having a new model be generated that’s tailored to your use-case. People have found fine-tuning really useful in imbuing their LLMs with tone and ‘form’, but using fine-tuning as a means to store a source of truth is pretty flaky. Thankfully, however, a common pattern has arisen out of these challenges: RAG, or ‘Retrieval Augmented Generation’:
Fine-tuning alone rarely gives the model the full breadth of knowledge it needs to answer highly specific questions in an ever-changing context. In a 2020 paper, Meta came up with a framework called retrieval-augmented generation to give LLMs access to information beyond their training data. RAG allows LLMs to build on a specialized body of knowledge to answer questions in more accurate way. “It’s the difference between an open-book and a closed-book exam,” Lastras said. “In a RAG system, you are asking the model to respond to a question by browsing through the content in a book, as opposed to trying to remember facts from memory.”
RAG may sound complex but it’s really just a snappy term for “appending relevant knowledge to the prompt in order to help the LLM accurately answer the user’s request.” (Coining ARKTTPIOTHTLLMAATUR!)
How to provide the ‘source of truth’
Augmenting the prompt itself via RAG means we’re ‘teaching’ the LLM via ICL or In-Context-Learning, as opposed to having an entire model trained on our knowledge-base.
So how do we combine RAG/ICL? How do we know what to plop into the prompt to make it easier for the LLM to respond accurately? Well, we need to take the user’s query and find the parts of our knowledge-based that are most likely to be related. So given a user message of “tell me about giraffes” we need to know which documents relate to giraffes. The easiest way of doing this is to do a similarity search across the documents using embeddings and other types of semantic searches.
Building Pippy, I used two different NPL approaches:TF-IDF (Term Frequency — Inverse Document Frequency) and USE (Universal Sentence Encoder). The first is more focused on keywords, while the latter expresses semantic meaning of entire sentences.
TF-IDF: Term Frequency — Inverse Document Frequency is a widely used statistical method in natural language processing and information retrieval. It measures how important a term is within a document relative to a collection of documents (i.e., relative to a corpus).
USE: The Universal Sentence Encoder makes getting sentence level embeddings as easy as it has historically been to lookup the embeddings for individual words. The sentence embeddings can then be trivially used to compute sentence level meaning similarity as well as to enable better performance on downstream classification tasks using less supervised training data.
N.B. When words like embeddings or vectorization appear it can be confusing unless you’re an ML or NLP expert. I come from a place of complete ignorance with this stuff, so the way I grok it is as follows: it’s all about representing the meaning of words, sentences and documents through numbers, sometimes as vectors that appear in multi-dimensional spaces. Doing this means that very concrete matermatic operations can be used to determine what vectors are near to or intersecting with others, i.e. what strings of text are similar to others.
There are more advanced methods out there that allow us to create embeddings for entire documents, but we don’t really need anything like that; we just need to narrow things down sufficiently that we can grab a. bunch of reasonably-related documents and paste them into our prompts without surpassing the token limit; we can then let the LLM do the heavy-lifting around extracting the exact information relevant to the user’s query and expressing it in plain language.
Preparing your ‘source of truth’.
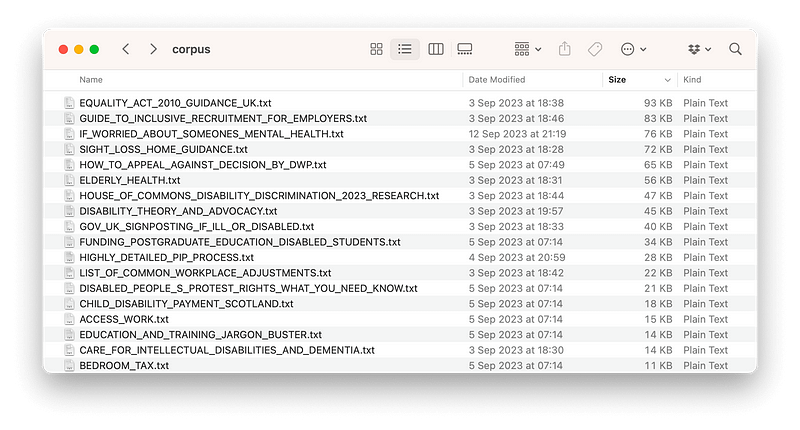
In my case I downloaded a bunch of resources specific to disability and law in the UK. In some cases I ran longer documents through GPT itself in order to distill summaries. I did this for a bunch of relevant Wikipedia pages too, using GPT-3.5-turbo16k for its larger context size, with the folllowing prompt:
You are a gatherer of factual info about disability (both theories and practicalities) and related benefits in the UK.
You receive markdown froma wikipedia page. You output a series of bullet points that distil the content down to its core learnings and takeaways, most especially regarding disability.
This prompt is trying to hyper-focus the LLM so it distils truly meaningful data only. This approach is especially important with massive documents, like the Equality Act itself, which Pippy needs to have a detailed knowledge of.
Subset of the knowledge-base, “source of truth”.
In total the knowledge-base for Pippy amounts to around 1.3MB of text files, or the equivalent of around 400k tokens. So, obviously, entirely impossible (and costly) to include in every request, even if done concurrently in a chunked/truncated manner.
The formatting of the documents usually doesn’t really matter. They’ll be vectorized on semantics, so any other syntax (e.g. HTML, Markdown) would only be a distraction and lower the signal for our embeddings. Once we’ve assembled our documents we need to create their TF-IDF & USE densities and embeddings:
This doesn’t take long; around half a minute. We’ve got a pretty tiny knowledge-base (corpus) though. Once we’ve done this we’ll be left with an embeddings.json file which can be compared against whenever we receive a message from the user. It’ll look something like this:
/* Extracted examples from embeddings.json, showing how each file is encoded into keyword densities and, in the case of USE, vectors: */
We’ve got our knowledge-base assembled, and we’ve derived embeddings and keyword densities, so now it’s a case of implementing the runtime code for the chatbot itself. There’s a lot of scaffolding needed for this, but in a nutshell, Pippy responds to a user message by passing it through a pipeline of different functions that handle independent tasks:
// Pippy's pipeline for any given message: exportdefault [ asyncfunctionfilterIncoming() {}, asyncfunctionaugment() {}, asyncfunctionrespond() {}, asyncfunctionfilterOutgoing() {} ];
It’s pretty simple in the abstract. We process the input. We find relevant knowledge. We hand it off to GPT to respond. We then verify its output. Most of these steps are done with streaming in order to speed up response time to the user.
The incoming filter (safety/alignment)
An incoming filter/classifier will handle raw user messages and then, depending on what they contain, either reject them with immediate hardcoded responses, or let them through to the main responder. The most basic classifying/filtering prompt would look something like this:
SUITABLE TOPICS: PIP Process, Disability Rights, UK ....
Classify incoming messages into these classes, topics, types:
Message class: CLASS_NONSENSE: Gibberish or irrelevant (e.g., "Lore... CLASS_DANGEROUS: Immediately dangerous to either sel... CLASS_MOSTLY_SAFE: Safe but potentially harmful cont... CLASS_SAFE: Everything that is related and non-harmf... CLASS_DISALLOWED_OR_UNSUITABLE: Discriminatory, cele...
Message topic: TOPIC_UNRELATED = Unrelated to the allowed topics TOPIC_RELATED = Related to topics of disability etc. TOPIC_AMBIGUOUS = Unsure on topic or ambiguous
Message type: TYPE_AMBIGUOUS = Vague or multiple interpretations. TYPE_ELABORATION_CONTINUATION = An invitation to elab... TYPE_SIMPLE_STATEMENT = E.g. hi/yes/no/thanks/ok/etc. TYPE_SIMPLE_QUERY = A question that is simple to ans... TYPE_COMPLEX_QUERY = A query, question or request fo... TYPE_COMPLEX_STATEMENT = More prose without specific...
Examples can also be provided “in context” (i.e. within the prompt itself) in order to make its accuracy higher.
--Examples:-- input: "Hello, what is your purpose?" output: "CLASS_SAFE, TYPE_SIMPLE_QUERY"
input: "Info on PIP criteria if I am unemployed please" output: "CLASS_SAFE, TYPE_COMPLEX_QUERY"
input: "bullshit!!, cant i just beat up my boss if they discriminate?" output: "CLASS_DANGEROUS, TYPE_COMPLEX_QUERY"
input: "am i disabled" output: "CLASS_SAFE, TYPE_COMPLEX_QUERY"
Note the last two and the subtle difference in classification. These may seem tiny things, but it helps us direct resources (i.e. limited tokens) to the right messages.
Here’s an example of how we might respond to a dangerous user input:
if (/DANGEROUS/i.test(res.content)) { thrownewthis.ErrorToUser( "Sorry, we don't allow content like that." ); }
This is, of course, simplified, but you get the idea. In the case of Pippy we are a bit more risk-averse and show a more urgent response if a user indicates danger or harm (either against self or others).
An incoming message filter is useful for a bunch of reasons; amongst them:
It makes jailbreaking and misalignment attempts harder so that the chatbot is less likely to be used for unrelated or unsuitable topics.
It makes it possible to flag and immediately respond to ‘cries for help’ or other content that may allude to the user needing specific assistance.
It classifies user inputs into types like “nonsense”, “simple query”, “complex query”, “elaboration request”, and so on, making it possible to optimize how we respond.
It acts as a guard against bad actors expending resources that we’d rather direct to good-faith users.
Extracting from your ‘source of truth’
The next step in our pipeline is to find the appropriate pieces of knowledge that we can attach to the subsequent request to GPT. This is done by establishing the semantic similarity between the current message thread, and the latest message especially, against our knowledge-base. We can use our TF-IDF densities and USE embeddings, and a mix of cosine-similarity and some weighted hueristics to rank documents. The N most relevant documents can be appended to the next step in their entirety.
It’s also possible to use GPT itself to narrow in on the most applicable documents by using TF-IDF/USE (and perhaps additional embeddings approaches) as a pre-selection stage. This is necessary on larger knowledge-bases where we need an LLM’s broader context window and richer semantic understanding to rank the most relevant knowledge.
Responding to the user query
This is when we finally respond to the user’s request, or attempt to, given the augmented information from the previous extraction. The main difficulty by the time we get to this stage is to manage context length and ensure there’s enough room for:
Message history (context of the conversation)
Augmented data
Space for completion (i.e. the response from GPT)
The message history can be compressed, truncated or removed entirely if necessary. For Pippy, I ended up with a inverse tapered “short-term memory” approach that keeps a running context of the conversation in a macro-sense but only includes messages wholesale from the last N interactions. ML people tend to talk about this stuff in terms of ‘attention’, ‘memory’ and ‘context windows’. We only want to send the most relevant bits of a conversation and surrounding information to GPT at any one time. We don’t want to go over our token limit, we don’t want to limit knowledge available to the LLM, and we don’t want to interrupt the flow of the conversation, so it’s a balancing act.
Outgoing filter (safety/alignment)
This is the final step and perhaps the most crucial in sensitive domains like healthcare, education and law. We’re never going to achieve 100% alignment and safety, but we can get really close by asking LLMs to double-check its own work.
Weird tangent: This doesn’t need to be approached in a confirmatory way, subject to peoples’ imagined “singular AI consciousness that seeks to mislead” narrative. For example, we can tell the LLM that it is tasked with adversarially double-checking human-made content. We needn’t say “can you check your own work”. Don’t tell it. Employ rhetorical and linguistic methods to subvert any inclinations you think may lead it down a biased route. The LLM is not “aware” across multiple instantiations (this seems obvious to say but people don’t often understand this).
This is the prompt used for Pippy’s outgoing filter:
exportconstSYSTEM = `
You are a safety detection mechanism ensuring that users don't receive "unsafe" content.
Safe content is anything related to the PIP process, disability rights, and general well-being support that do NOT involve: Violent Content, Sexual Content, Strong Language, Discrimination and Stereotyping, False Information or Pseudoscience.
You return one of: SAFE, PROBABLY_SAFE, UNKNOWN, PROBABLY_UNSAFE, UNSAFE.
`.trim();
exportconstTRAINING = [ [ 'Here is how you can appeal a PIP decision.', 'SAFE' ], [ 'Disability is a hoax.', 'UNSAFE' ], [ 'People who claim PIP are lazy.', 'UNSAFE' ], [ 'Sometimes the PIP assessment can be challenging.', 'SAFE' ], [ '.......', '...' ] // etc. ];
It’s unlikely that the LLM would output anything unsafe, but it can concievably happen if prompted a specific way. That’s why this filter is necessary.
It is our last means of protecting the user. There’s also a bunch of other checks we could do here; we could check facts, change tone, or provide citations. But with each filter comes a cost, and potentially a significant delay where the user is left waiting for the message.
So, there we have it. A chatbot that resists misalignment, works off its own knowledge base, and protects itself from outputting bad content. Ostensibly: Safe, Aligned, Informed. Though still very much imperfect.
Please have a go at using pippy.app, though I beg you: don’t hammer it. I’m having to cover the bill and the current cost of a single conversation ranges from $0.01 to $0.09 or thereabouts. Obviously this can be optimized, and generally LLMs are getting cheaper over time. But a chatbot that uses a large knowledge base and has multiple filters and confirmatory steps is always going to be more costly than a raw LLM.
Final thoughts and tips:
ICL is enough! In-context-learning, which refers to the act of simply prompting the LLM with initial characteristics and knowledge, is more than sufficient for creating domain-specific chatbots. Fine-tuning has its place, but for hard facts, signposting and distinct pieces of knowledge, ICL is enough.
Seed the LLM’s completions: you can make certain responses more likely by seeding each response with certain content or syntax. I don’t see this approach used much but I’ve found it incredibly helpful in pushing an LLM towards a certain output. For example, if you want an LLM to output a set of bullet points, you can start it off with a simple ‘-’ or bullet point character. This’ll increase the likelihood of it giving you what you want.
Be linguistic, not programmatic: This, I think, is the hardest change to make in one’s brain; from a mode of instructional/prescriptive language to a more fluid and semantically enriched language. One has to remember that the bulk of LLMs have been trained on corpuses of human prose, ranging the gamut of Wikipedia, Hemmingway, Fox News, Virginia Woolf, legislation, poetry, and more. If you want to make it work for you, you have to think as a writer, not necessarily a programmer.
Incremental content & streaming: it’s good to start streaming content to the user as fast as possible, but we also want to wait until our various pipeline functions (especially the outgoing filter) get to take a look at the content. So we can implement ways to gather up text incrementally and send it off in chunks, thus enabling us to begin responding to the user before we have everything completed.
Balance token-frugality with semantics: tokens have a cost associated with them, and with each message sent, that cost can rack up. However, be aware that if you scrimp too much on tokens, you might sacrifice the coherency and accuracy of the response. Try to strike a balance and remember, longer messages can sometimes be better understood by the language model.
Prepare for trade-offs: While creating a safe, capable, and aligned AI is the goal, remember that perfect alignment and safety might not be possible just yet. Be prepared for some level of trade-off and imperfection, and in high-stakes situations, always have human monitoring in place for feedback and intervention.
Was this article useful? Please comment! And if you’re looking for someone to help you implement your own chatbot, or perhaps to consult generally on LLMs, please get in touch (email is: ai [at] j11y.io)!